
Music Signal Enhancement
This year at ICASSP we’re presenting a novel technique to enhance a music signal via generative adversarial networks and diffusion probabilistic models.
The goal is to remove undesired noise and reverb while enhancing certain frequencies to make the signal as clean and crisp as possible before any potential addition of sound effects.
Here some examples:
(The original videos were obtained from here and here –the one in the middle was recorded by yours truly :-))
To do so, we used MedleyDB-Solos to train a GAN to discriminate between clean, professionally recorded solo tracks and noisy clips with solo instruments.
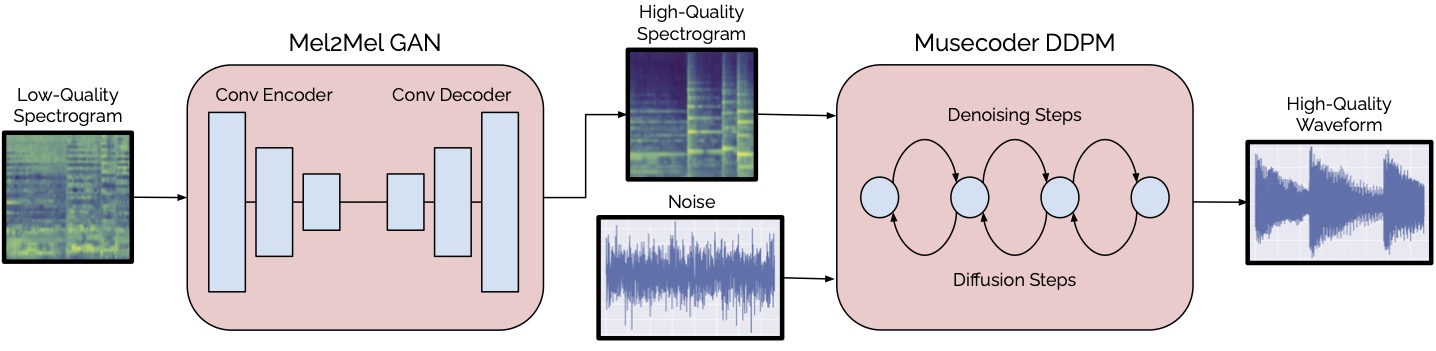
Once the GAN is trained, we can feed it a noisy music signal to obtain an enhanced spectrogram. Such spectrogram is then passed through a diffusion probabilistic model that serves as a music vocoding (we call it musecoder, because we’re fancy), to generate the final waveform.
The full architecture overview is here:
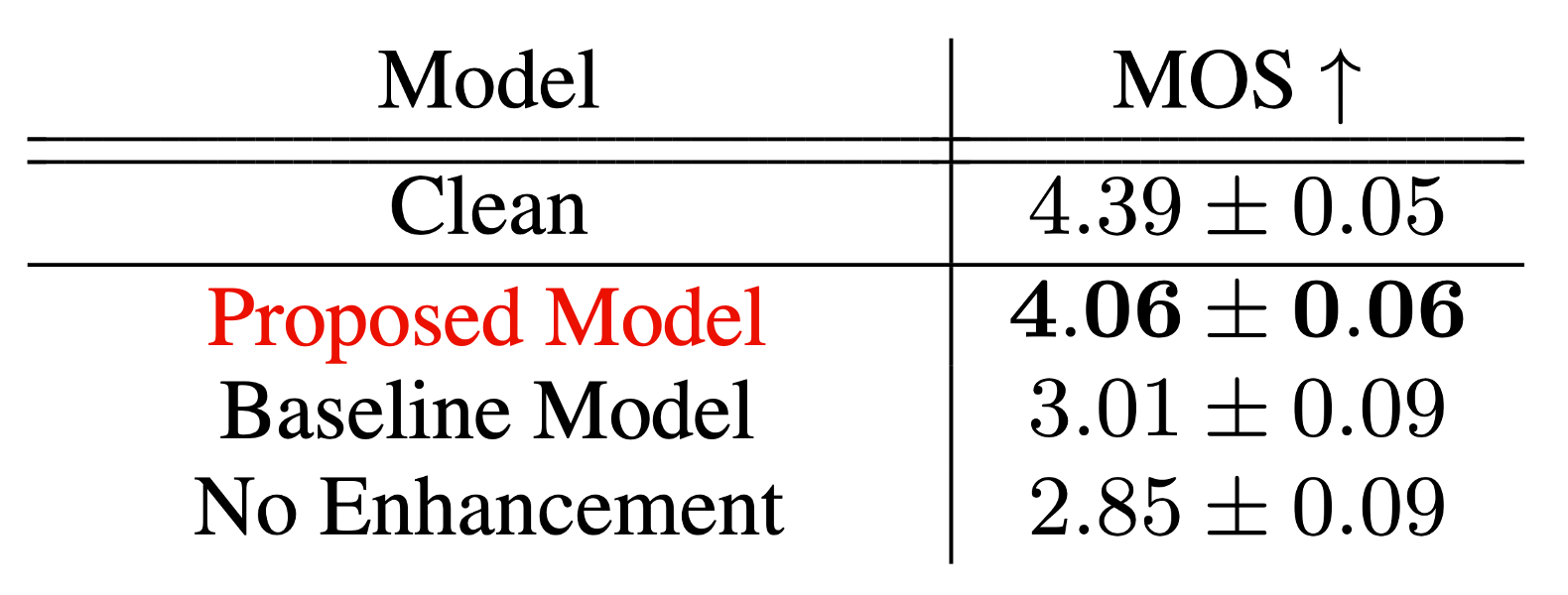
We performed a survey with over 200 participants to rate the audio quality of our proposed technique. The results in terms of Mean Opinion Scores show that the output of our model is closer to the quality of professionally recorded musical instruments compared to other baselines, thus obtaining state-of-the-art in terms of music signal enhancement.
You can find the source code, pre-trained models, and more demos in the official page: https://nkandpa2.github.io/music-enhancement/
For more details, you can read the full article here:
Kandpal, N., Nieto, O., Jin, Z., Music Enhancement Via Image Translation and Vocoding, Proc. of 47th International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Singapore, 2022 (PDF).