
Mood Classification Using Listening Data
For my paper of this year’s ISMIR I’ve had the real pleasure to join forces with a titanic set of humans from Pandora, MTG-UPF, and Netflix to bring up this work to life: Mood Classification Using Listening Data.
The main idea behind it originated when Erik and I worked on Pandora’s Personalized Mood Soundtracks (which, without bragging too much, won the “Best Use of Machine Learning” Webby Award last year). We realized that by employing data learned from listening behavior we could predict the mood that a given track might evoke with much more accuracy than by analyzing the actual audio content itself. And this is what we show in the paper, but here you have a sneak peek:
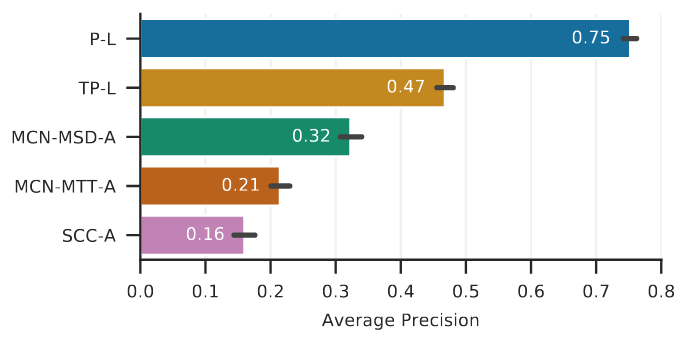
Without going too much into details, the models marked as *-L above are trained using only listening-based data, while the ones tagged as *-A employ only audio content. This is quite remarkable, since it shows that listeners tend to be consistent in the type of moods that their favorite music might evoke. So, MIR researchers: if you want to retrieve mood information from a song, embeddings from listening interaction data will give you much better performance.
But wait, there’s more.
For transparency’s sake, we gathered data from publicly available datasets and compiled them in a new moods data set that we call the AllMusic Moods Set. This is a set of ~67k tracks that have the following data for each track:
- Artist, Song, and Track ID from the Million Song Dataset.
- Track embeddings from the factorization of the Taste Profile data.
- Track embeddings from two different MusiCNN models.
- 30 second audio previews from 7digital.
- Mood data annotated by human experts that can be retrieved from AllMusic.
All of these data, plus the code to replicate our experiments can be found in this github repo: https://github.com/fdlm/listening-moods
Overall, I am particularly happy about this publication, and I hope ISMIR attendees find it useful. And here I leave you with Filip, the other main author of this work, with the video that will be (virtually) presented next week:
Also, if you’re attending ISMIR, come and say hi in our poster 4-10 (that is Tuesday and/or Wednesday, depending on your timezone).
And finally, here you have the full citation:
Korzeniowksi, F., Nieto, O., McCallum, M., Won, M., Oramas, S., Schmidt, E., Mood Classification Using Listening Data, Proc. of 21st International Society for Music Information Retrieval Conference (ISMIR), pp542–549. Montreal, Quebec, Canada, 2020 (PDF).
Looking forward to ISMIR 2020!