
Audio-Text Models Do Not Yet Leverage Natural Language
TL;DR: we thoroughly analyzed state-of-the-art audio-text multimodal models and they do not fully leverage natural language. Read our new ICASSP 2023 paper here.
More specifically, such models struggle at understanding both ordering and simultaneity. What’s worse is that current evaluation benchmarks are not capable of assessing these important features of natural language, so the “best” models based on such benchmarks are not really properly assessed (they are pretty much learning “horses”). This all combined is the perfect recipe for general confusion and mass frustration in the exciting field of audio research.
But worry do not! In this work we show how Transformer-based architectures can alleviate such problems (i.e., feel free to ditch that old-school MLP projection on top of your audio-text models). Furthermore, we make the case that, if we were to have more high-quality data, such models could yield even better results.
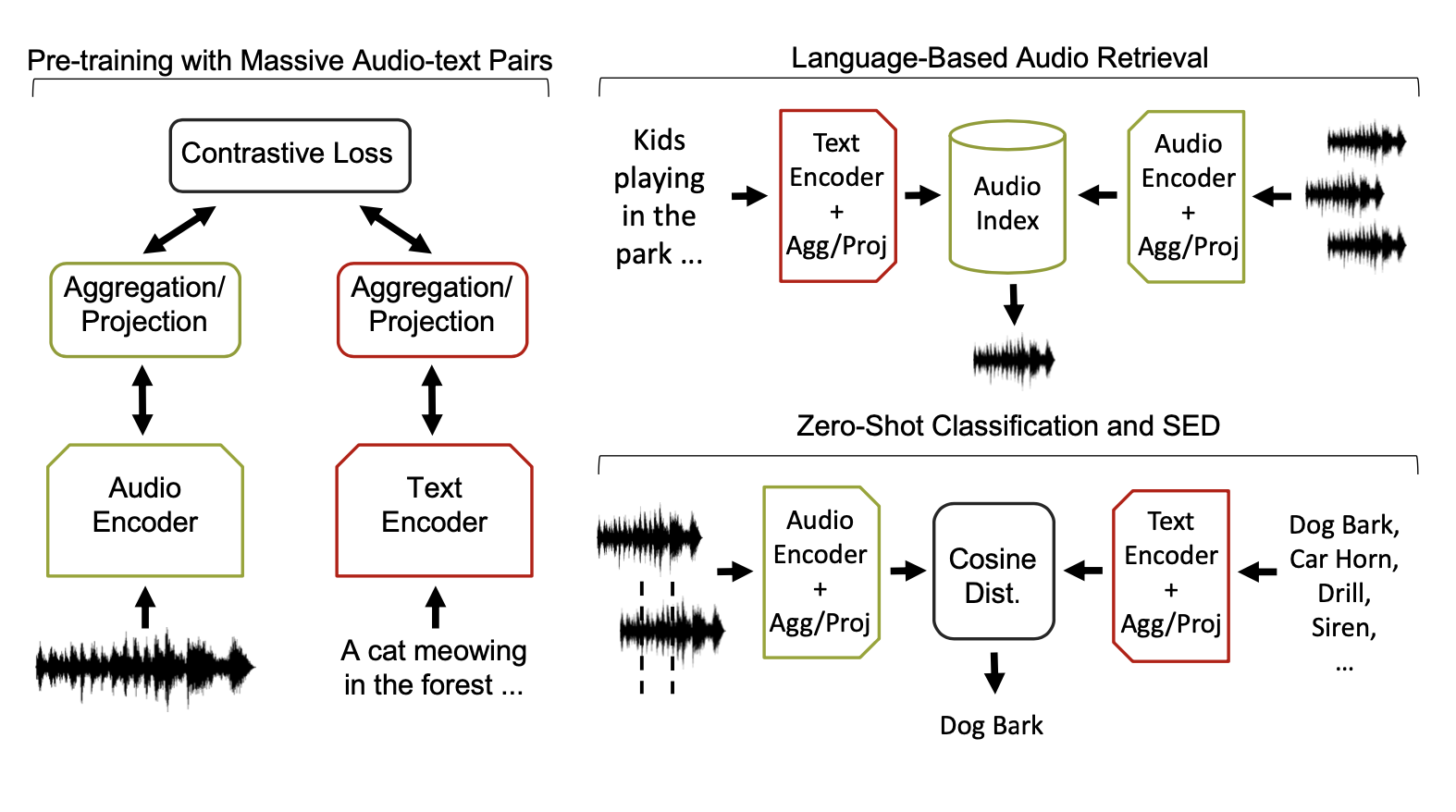
We analyze the models in three different scenarios: retrieval, zero-shot, and sound event detection. We compare an MLP projection vs a Transformer projection on top of all of these tasks. The architectures for our methodology are depicted as follows:
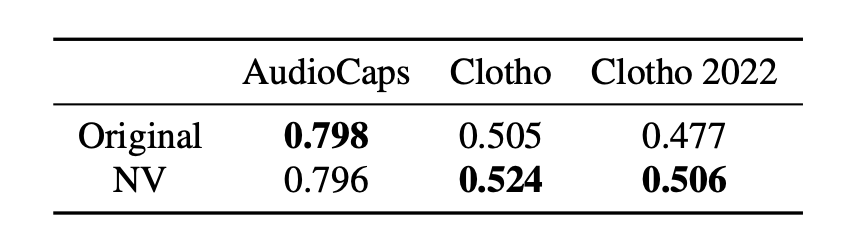
The first interesting finding is that these models have no idea about anything beyond verbs and nouns. We filtered out everything besides these two types of words from the training data and the results are pretty much identical or, even more surprisingly, slightly better for some datasets (“Original”: all words; “NV”: Nouns and Verbs only):
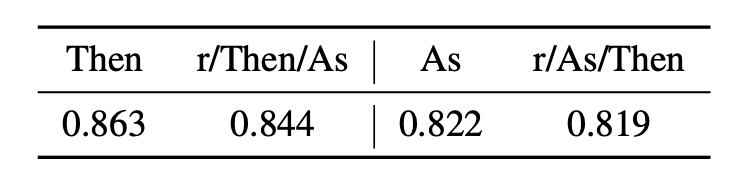
Moving on, those SOTA models with MLP projection layers are not capable of detecting simultaneity. How do we know? Well, we swapped the content before and after sentences containing “then” or “as” and the results are basically the same:
But thank Google that Transformers are here to save the day! We swapped the content of sentences containing “before” and “after”, in order to understand how well our models understand ordering. Turns out Transformers do understand this crucial concept, as we see they outperform MLPs on such sentences, and they yield much worse results when using swapped sentences. On the other hand, MLPs perform similarly on the original vs swapped sentences. Why, you may ask? Well, because MLPs don’t give a shit about ordering (they’re just mean –poolers. ha!).
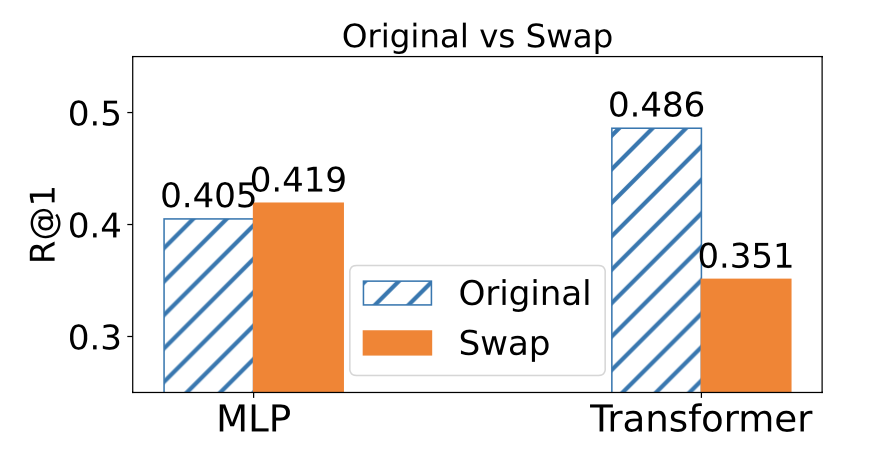
Moreover, we did a –dare I say pretty cool– experiment where we checked which sentences were closer: the original or the swapped ones? Random guessing would be 50%. We clearly see the same trends: MLPs don’t care about ordering, Transformers do. What’s more interesting is that, given more augmented data with the concepts of ordering in them, Transformers yield even better results (they are really data hungry creatures):
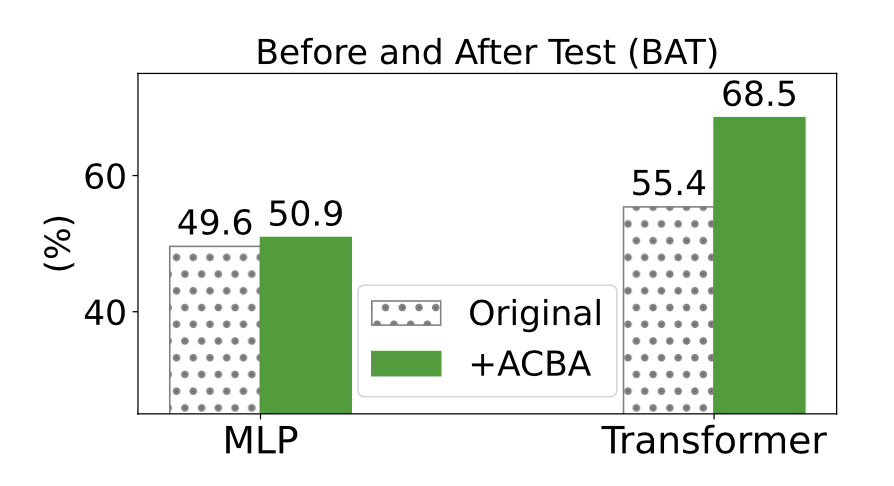
And despite all of this, when we evaluate the terrible MLPs on official benchmark datasets, what do we observe? That they are… the best! lol. Clearly we need better datasets to evaluate audio-text multimodal models, and hopefully this work clearly illustrates it with this final table:
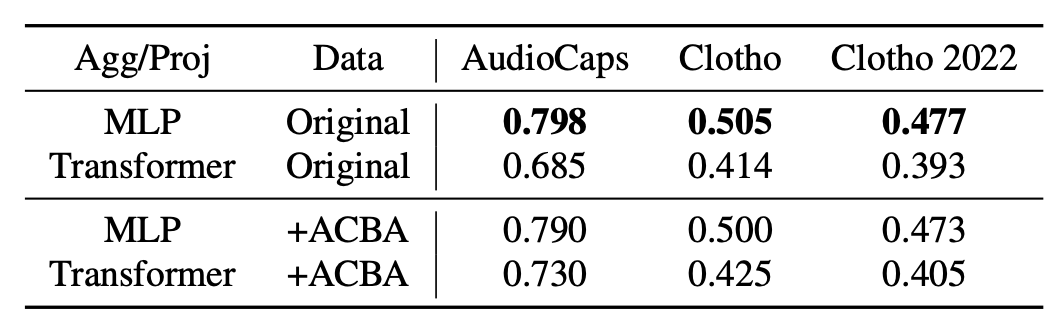
We hope we have convinced you to use Transformers and to strive for better data when working with audio-text multimodal models. And also, I hope to see you at ICASSP next week, we’re gonna be presenting this in the afternoon session on Tuesday in the beautiful island of Rhodes in Greece. See you there, titans!
Full reference:
H. Wu, O. Nieto, J. P. Bello and J. Salomon, “Audio-Text Models Do Not Yet Leverage Natural Language,” ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023, pp. 1-5, doi: 10.1109/ICASSP49357.2023.10097117 (PDF, BibTeX).