
The Best of RecSys 2020
It was long overdue, but I have finally been to RecSys for the first time. I heard so many great things about this conference, and it is so closely related with my day to day job, that it was embarrassing to admit that I had never attended before. And, while I was hoping to be drinking caipirinhas in Rio at the end of everyday of presentations, attending from my room due to Covid-19 was not that bad. And, I must say, the rumors were true: this conference was truly inspiring and organized by such an amazing community of researchers. Best virtual conference I’ve ever attended (and for better or worse, this is the third one). Also, the karaoke session was epic.
Here I attempt to compile the set of papers/talks that I found most interesting.
Keynotes
There were three keynotes this year, but if I were to pick one, I would choose 4 Reasons Why Social Media Make Us Vulnerable to Manipulation by Filippo Menczer from the OSoMe group.
Spoiler alert, the 4 reasons are (from more to less worrisome):
- Manipulation
- Platform bias
- Information Overload
- Echo Chambers
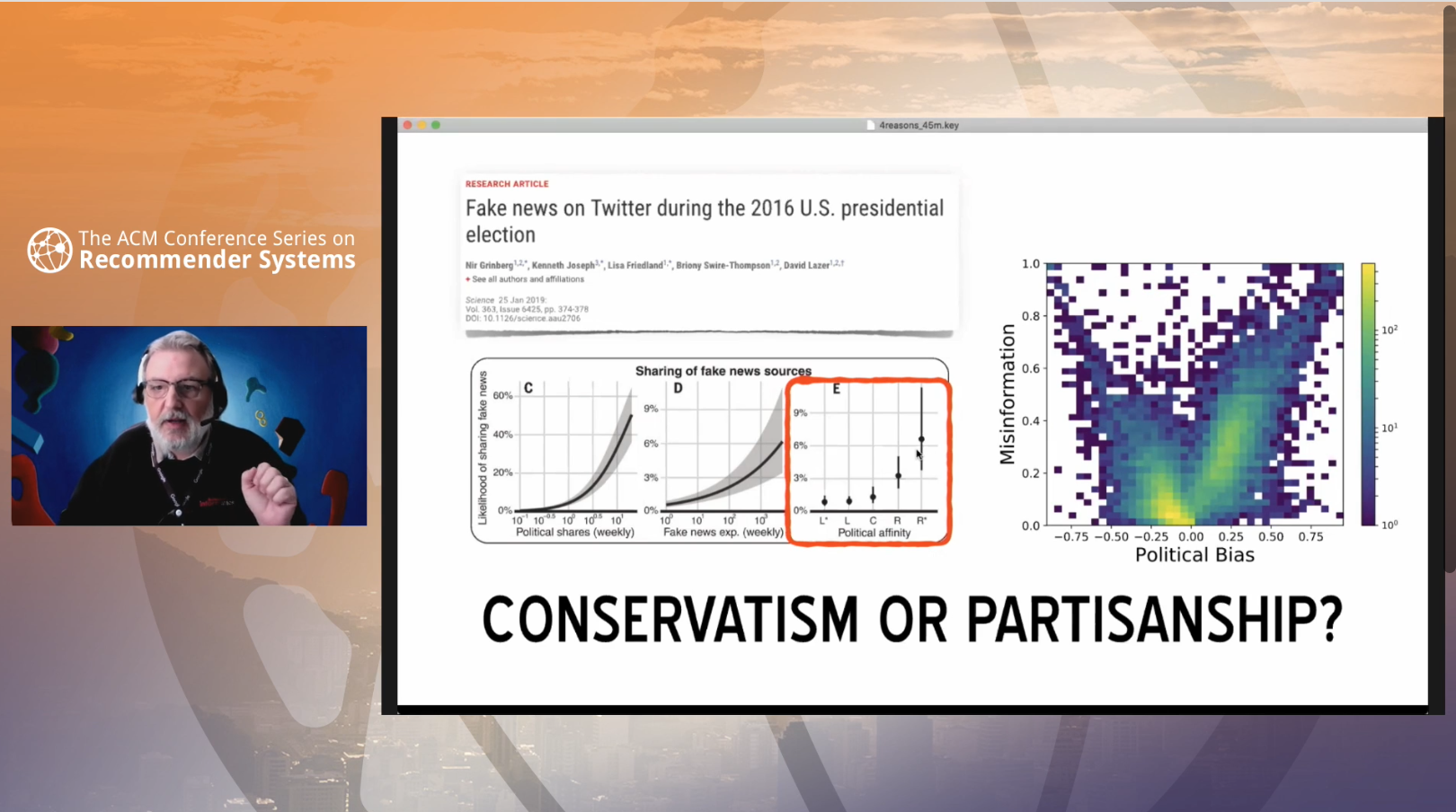
This topic couldn’t be more timely. The keynote was eye-opening and jaw-dropping. Researchers on recommender systems have a big responsibility at trying to fully understand and overcome these vulnerabilities as much as possible. The world is likely a much worse place today because these problems haven’t been addressed enough.
Interestingly, it has been just relatively recently when the problem of bias and fairness has become more prevalent in the field of Machine Learning in general (with the outstanding keynote delivered by Kate Crawford at NeurIPS 2017 –and the 2016 US elections– having a lot to do with it). I am happy to see that these topics are now central to most conversations not only at RecSys, but in NeurIPS and ICML.
I am uncertain what the policy of RecSys is in terms of publishing their sessions, but I do hope they make this keynote available to everybody.
Papers
Here I list my top 10 RecSys 2020 (long and short) papers. Sorted alphabetically.
Carousel Personalization in Music Streaming Apps with Contextual Bandits
Cool application of contextual bandits in a “Carousel” music application, tested in a large-scale scenario by the good people at Deezer. They not only report how effective their model is, but they also release a publicly available dataset and an open-source carousel personalization environment to play with. The code and dataset should be here “by the end of September 2020.” This makes me both happy and sad: happy because I see that I’m not alone in terms of doing research at the very last minute (it’s September 28th and the repo is still empty); sad because the code isn’t available yet and the world would be a much better place if researchers wouldn’t do things at the very last minute.
Content-Collaborative Disentanglement Representation Learning for Enhanced Recommendation
Do you want to combine content and collaborative features together? Disentangle them first! This paper proposes a two-level disentanglement model that makes use of the KL divergence to ensure that the learned features are statistically independent. Results obtain state-of-the-art on 3 different datasets.
Exploring Longitudinal Effects of Session-based Recommendations
Interesting “reinforcement effect” investigation on music recommendation. The authors run several algorithms in a repeated manner and report how, in the long term, recommenders tend to pick smaller pools of songs because they keep recommending more and more similar tracks due to the reinforcement effect. By running a re-ranking method, they are able to reduce this potential bias in the recommendations.
KRED: Knowledge-Aware Document Representation for News Recommendations
Graphs! Really interesting work that improves embedded representations of news items by employing knowledge graphs. These representations could later be fed to a MMOE-like system as a new set of features to better recommend items. The model is tested in Microsoft News and yields better recommendations than their baselines. I can see how this could have a lot of potential in terms of music recommendation, especially if a genre knowledge graph is available.
MEANTIME: Mixture of Attention Mechanisms with Multi-temporal Embeddings for Sequential Recommendation
I picked this one up mostly because of its wonderful acronym. Just kidding. This work, as many others, makes use of a Transformer model, enhancing it by improving the positional encoding mechanism. This allows to have richer contextual embeddings as input, and thus resulting in better performance. I particularly liked how they enforced the day of the week to be encoded as part of the model (this makes so much sense, especially when recommending music!).
Neural Collaborative Filtering vs. Matrix Factorization Revisited
Aw, the people at Google always publishing great stuff. This one is simple and clear: use a dot product instead of MLPs on top of your architectures to have not only better recommendations, but also better computational performance. So, if you are to use Neural Collaborative Filtering, put a dot product at the end, don’t overcomplicate your pipeline.
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations
The idea of solving several tasks at the same time (Multi-task learning or MTL) is highly appealing to several practitioners in the field. Based on the highly influential MTL MMOE model, this new proposed method better learns each of the tasks jointly as opposed to “hurting” other tasks while improving others. They apply this new model to a dataset by Tencent and the results show a significant performance gain. Best Paper Award (and I promise I marked this one down before they announced the winners. Happy to see my bias is not too different from that of the experts who give away these awards!).
PURS: Personalized Unexpected Recommender System for Improving User Satisfaction
This one is about personalized discovery. Or, as the authors put it: “presenting fresh and previously unexplored items to the users.” They present a definition of “unexpectedness” by clustering the user latent space and apply it to a model that employs the self-attention mechanism. They beat state-of-the-art in open datasets and in the Alibaba-Youku video platform via A/B testing.
SSE-PT: Sequential Recommendation Via Personalized Transformer
Based on the SASRec model, the proposed SSE (Stochastic Shared Embeddings) model adds personalization to the whole thing. The cool trick is to include user embeddings as input as well as the items to be recommended in a Transformer model, stochastically during training. This makes the model yield ~5% performance increase on 5 different datasets.
TAFA: Two-headed Attention Fused Autoencoder for Context-Aware Recommendations
This work aims at addressing the popularity bias usually introduced in autoencoders that operate on implicit feedback. To do so, they apply an attention mechanism to user reviews to obtain better reviews representations jointly with implicit feedback in a two-headed model. This yields a “de-popularization” of the autoencoders, and moreover offers potential explanations as to why a given item was recommended. Code is openly available.
Tutorials
I only attended the Feature Engineering for Recommender Systems tutorial, but I would highly recommend it. The team from NVIDIA delivered a highly educational presentation on how to better engineer your features before you fit your models.
Some remarks:
- CuDF seems a wonderful pandas alternative that runs much more efficiently on GPUs.
- The notebooks from the tutorial are publicly available and they’re very easy to follow and yet contain a high degree of detail that should satisfy both newcomers and seasoned practitioners.
- The increases on performance on their Kaggle dataset example thanks to feature engineer are above 13%.
Expos
Pandora’s expo was by far the best one. No biases here. Here’s a little screenshot that the titan Xavier Amatriain poster on twitter:
(Yes, I wrote a song for RecSys. Might post it here some day if there’s enough interest.)
Seriously, though, the demo that my colleague Chun Guo gave on Voice Personalized Search was actually pretty amazing. Makes me so proud of the work we’re doing at Pandora!
I heard great things about the Netflix expo too, but unfortunately I had some technical difficulties (Whova! is weird) and couldn’t attend.
Conclusions
RecSys 2020 has been such a fantastic conference. I think it’s the perfect balance between content and size. Content, because I’m highly interested in most sessions of this highly targeted conference. Size, because it never felt overwhelming in terms of number of people / publications / sessions. Rather the opposite, it reminded me of ISMIR, where attendees are typically really approachable and the sense of collaboration is always in the air (I still think ISMIR is the best conference ever, but I guess that deserves its own post).
I will take this chance to thank the organizers and presenters for this extremely inspiring event. And also Pandora, for letting me attend.
See you again next year, hopefully in person!